29 results for open calais python
 Open Calais - a new and smart API from Reuters - finally does what critics say to be the greatest obstacle to the Semantic Web: Taking the metadata burden from the end-user by providing an automatic meta-tagging tool. The principle behind Open Calais is easy: Put in some unstructured text and get in return nicely structured RDF-data. Backed by powerful Text Mining and machine learning techniques the API automatically detects entities like persons, events, countries and other facts.
Open Calais - a new and smart API from Reuters - finally does what critics say to be the greatest obstacle to the Semantic Web: Taking the metadata burden from the end-user by providing an automatic meta-tagging tool. The principle behind Open Calais is easy: Put in some unstructured text and get in return nicely structured RDF-data. Backed by powerful Text Mining and machine learning techniques the API automatically detects entities like persons, events, countries and other facts.
Open Calais takes account of the fact that the added value of content is hidden in its structure. Uncovering that structure and representing it in a interoperable format makes existing resources more programmable and reusable.
But what is in for Reuters? Nothing less than the biggest structured content repository on the web. Should not we talk about this little fact as well?
11 months ago I posted a short entry that posed the question of whether the world needed a metadata extraction service. I stated that the service could quickly become the largest repository of metadata (in the form of named entites and facts) on the Web if it stored the resulting metadata from each request. Open Calais seems to me to be the "metadata extraction service" I had in mind; it's is a Web service that allows you to automatically annotate content and extract information like facts and named entities (people, places, and organizations, and much more) from unstructured text. If that weren't enough of a good thing, Open Calais returns the metadata in RDF.
Although the question of whether we need it still hasn't been answered, I believe this service could be a catalyst for change towards Semantic Web standards if it is integrated into (or used to create plugins for) the multitudes of open source blogs and other CMS software. Open Calais opens the door to the possibility of lowering the barrier enough for everyday users to publish semantic content.
The Calais Initiative is almost one month old, and they've already received a large and welcoming response from the development community (1,113 early adopters)! When they weren't busy doing interviews or answering hundreds of emails and forum posts, they were coming up with ways to help spread the technology. They will soon be releasing a Wordpress plugin, followed by plugins for Drupal, Plone and other content management systems. They also express that Calais is not only good for named entity extraction, but can extract other facts from documents. An example they give is "what technologies are associated with what company in a document?" Good luck, Calais team!
Today finally I logged in to Twine the first time. I was reading yesterday about some shortcomings of the system, so I was keen on trying out the system by myself to get my own impression.
It's true that the system isn't as easy to understand as del.icio.us or other bookmarking tools. It takes a while until you get used to all those additional ways you can navigate through the system. Remember: "Twine looks at content and parses it automatically for the names of people, places, organizations and other subject tags. Users are then able to navigate between related content, view recommended content and connect with recommended people with related interests."
Continue reading My First Experiences with Twine
 Freebase stores millions of entities and assertions about nearly every topic one can ponder (thanks are owed to their seed dataset – Wikipedia – and their amazing community). The amount of information that Freebase stores is incredible, and is a testament to what can be accomplished with the help of a dedicated community and a little (or a lot) of clever software engineering.
Freebase stores millions of entities and assertions about nearly every topic one can ponder (thanks are owed to their seed dataset – Wikipedia – and their amazing community). The amount of information that Freebase stores is incredible, and is a testament to what can be accomplished with the help of a dedicated community and a little (or a lot) of clever software engineering.
Continue reading Can Graphd Scale to Meet Semantic Web Demands?
Many visitors to blogs are turning to feed readers for consuming their favorite content. Are we looking at a change in how we should judge the traffic of a Website? We are already seeing advertisements appear in feeds which helps solve the issue of monetizing feeds, which is especially beneficial to bloggers who prefer to give full feeds.
Continue reading Is feed-only consumption an issue for bloggers?
The Semantic Web Company in Vienna, Austria is giving away a full conference pass worth $1,095 for the LinkedData Planet Conference! LinkedData Planet 2008 will be taking place on June 17-18, 2008 in New York with confirmed keynote speakers Sir Tim Berners-Lee, Kingsley Idehen and Ian Davis.
Continue reading Win a Full Conference Pass for LinkedData Planet 2008
 Semantically-Interlinked Online Communities (SIOC for short) is a framework aimed at connecting online communities and discussions from blogs, forums, content management systems mailing lists, and anything else. In the current Web, communities such as forums and blogs are like islands - they contain valuable information but are not well connected or queryable. SIOC allows you to connect these sites, and enables the extraction of semantic information from unlimited discussion platforms.
Semantically-Interlinked Online Communities (SIOC for short) is a framework aimed at connecting online communities and discussions from blogs, forums, content management systems mailing lists, and anything else. In the current Web, communities such as forums and blogs are like islands - they contain valuable information but are not well connected or queryable. SIOC allows you to connect these sites, and enables the extraction of semantic information from unlimited discussion platforms.
Continue reading Connect Discussions Between Blogs, Forums, and more with SIOC
 Before I started researching the Semantic Web I spent a few years as a hobbyist game developer. In fact, if you'd asked me 4 years ago what I'd be doing today I would have said "working on a game engine." I still enjoy game development and (naturally) playing video games as well. I often wonder how the Semantic Web will affect game development, and how games may take advantage of Semantic Web technologies. I've searched high and low (on Google) and haven't found a single written piece on people's ideas of the Semantic Web and video games so I will describe my own, as well as provide some visuals to give you a clear picture.
Before I started researching the Semantic Web I spent a few years as a hobbyist game developer. In fact, if you'd asked me 4 years ago what I'd be doing today I would have said "working on a game engine." I still enjoy game development and (naturally) playing video games as well. I often wonder how the Semantic Web will affect game development, and how games may take advantage of Semantic Web technologies. I've searched high and low (on Google) and haven't found a single written piece on people's ideas of the Semantic Web and video games so I will describe my own, as well as provide some visuals to give you a clear picture.
Continue reading Possibilities for Video Games and the Semantic Web
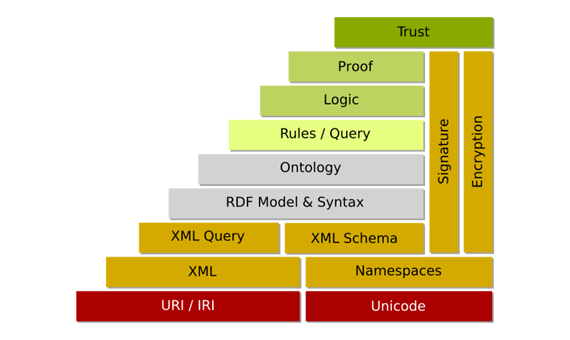
 In Part 2 of this series we reviewed Unicode, URI, and XML - three foundational technologies that permeate the existing Web and that are especially relevant to the emerging Semantic Web. We will put all three to use as we take our next step up the Semantic Web layer cake in a review of the Resource Description Framework (RDF). At the same time, we will be taking the visual RDF/OWL editor, Altova SemanticWorks, for a test drive. Since I will be using this tool for the very first time, you can expect an honest review that is rich with screenshots. If you do not already have the software, you may wish to download the trial version now so you can follow along.
In Part 2 of this series we reviewed Unicode, URI, and XML - three foundational technologies that permeate the existing Web and that are especially relevant to the emerging Semantic Web. We will put all three to use as we take our next step up the Semantic Web layer cake in a review of the Resource Description Framework (RDF). At the same time, we will be taking the visual RDF/OWL editor, Altova SemanticWorks, for a test drive. Since I will be using this tool for the very first time, you can expect an honest review that is rich with screenshots. If you do not already have the software, you may wish to download the trial version now so you can follow along.
Continue reading Introduction to the Semantic Web Vision and Technologies - Part 3 - The Resource Description Framework
Recent searches
semantic, semantic web search, microsoft semantic web, semantic web blog, semantic focus, semantic web search engine, semantic web problems, semantic cms, semantic web search engines, semantic web, semantic web blogs, camp semantic, semantic web layer cake, natural language processing blog, semantic web microsoft, sparql php, semantic blog, natural language search, true knowledge, eswc 2009, object oriented web, protege tutorial video, rdf tags, introduction to semantic web, php sparql, microsoft rdf, microformats rdf, semantic web conference 2008, owl semantic web, problems with semantic web, rdf vs microformats, cody burleson, protege tutorial, rdf search engine, microformats vs rdf, rdf microformats, semantic web tutorial, semantic web conference 2009, rdf blog, eswc 2008, graphd, rdf microformat, semantic web rdf, blog semantic web, semantic web conference, european semantic web conference 2009, dbpedia freebase, web service life cycle, semanticfocus, python sparql, problems in semantic web, swoogle, curse of knowledge, semantic web introduction, semantic web issues, statistical search, semantic web layers, semantic web vision, twine blog, semantic web podcasts, owl videos, rdf tagging, semantic web natural language processing, arc rdf, falcons search engine, protege 4 tutorial, web videos, european semantic web conference 2008, semantic search engine, semantic web community, semantic web tutorials, semantic natural language processing, semantic web problem, semantic web videos, microformat rdf, natural language processing semantic web, web search engines, open calais, problems with the semantic web, rdf tag, semantic web cake, web thread, tower of babel, bin laden, rdf microsoft, semantic web technology stack, natural language processing blogs, natural language question answering, rdf owl, protege screencast, semantic web logo, problems of semantic web, information extraction blog, microformat vs rdf, protege video tutorial, domain knowledge, james simmons, seesaw effect, semantic search, semantic web references, the curse of knowledge, web 3.0 ideas, web semantic, blog semantic, cms tags, question answering, semantic web games, semantic web technology, aditya thatte, rdf video, spanish semantics, web evolution, data storage in oracle, different from, freebase rdf, microsoft and semantic web, problems semantic web, rdf vs microformat, web search engine, what is true knowledge, freebase dbpedia, jamie lewis blog, question answering wikipedia, semantics, web service ontology, zitgist, freebase linked data, introduction to semantic web vision and technologies, ontology blog, owl introduction, protege semantic, selfishness, semantic update, semantic web protege, focus semantics, freebase vs dbpedia, microformats and rdf, microformats vs, microformats vs semantic web, owl tags, protege semantic web, search engine semantic web, semantic web owl, altova tutorial, backlinks blog, calais initiative, eswc 2008 semantic, protege, semantic web microformats, semantic web research topics, semantic web technologies, arc semantic, natural language semantic web, oracle semantic web, owl semantic, problem with semantic web, rdf, semantic web layer, semantic web tags, service ontology, sparql python, vertical search engines, web blogs, blog rdf, cms semantic, dbpedia vs freebase, hyperdata, natural language processing semantics, ping the semantic web, python semantic web, rdf and microformats, semantic search engines, semantic search example, semantic web services, web object oriented, wikipedia question, wordpress semantic web, information extraction, international semantic web conference 2009, list of vertical search engines, microformats, microformats versus rdf, natural language processing, natural language processing wikipedia, object oriented web page, semantic conference 2008, semantic conference 2009, semantic web conferences 2008, semantic web conferences 2009, semantic web feed, semantic web video, social semantic web, w3c logo, web introductions, webblogs, evolution of semantic web, iri semantic web, issues in semantic web, language question, natural language question answering system, on whose vision is the semantic web concept based, oracle data storage, protege 4.0 tutorial, protege ontology, rdf versus microformats, search engines, search semantic web, semantic data storage, semantic web reference, service, web 3.0 opportunities, web services life cycle, aperture semantic, backlink blog, blog semantics, falcons semantic, hl, introduction of semantic web, leave a comment, legs blog, list of blogs, microsoft semantic web, natural language processing semantic, problem of semantic web, problem semantic web, protege tutorials, rdf blogs, rdf review, semantic web 101, semantic web conferences, semantic web natural language, semantic web podcast, semantic web searches, semantics is, service life cycle, service ontologies, vertical search engines list, web conference 2008, wikipedia natural language processing, arc semantic web, blog natural language processing, european semantic web 2008, foaf search, international semantic web conference, international semantic web conference 2008, introduction to semantic, iswc 2008, life cycle of web services, metadata extraction and tagging service, microformats tags, microsoft sparql, object oriented web pages, owl vs rdf, semantic news aggregator, semantic web 2009, semantic web algorithm, semantic web evolution, semantic web game, semantic web layer cake 2008, semantic web service, semantic web sites, service modeling, spanish semantic, sparql in php, tassilo pellegrini, the nature of selfishness, the semantic web is not a separate web but an extension, tutorial protege, camps semantics, eswc 2008 conference, eswc 2008 semantic web, falcons semantic web search engine, freebase, lowell vizenor, metadata extraction, natural language question, nature of selfishness, object oriented web site, oracle semantic store, owl rdf, pagead2.googlesyndication.com, problems of the semantic web, protege 4, rdf vs. microformats, search engines semantic web, semantic logo, semantic markup tags, semantic web searching, semantic web tools, spanish language semantics, starting a revolution, swoogle.com, tag rdf, the semantic web vision, web service lifecycle, wikipedia question answering, arc php, arc rdf php, blogs semantic web, dbpedia, focus, folktologies, microformats vs. rdf, mining tags, ontology, open calais python, podcast semantic web, problem in semantic web, protege introduction, rdf semantic web, search engine for semantic web, selfishness of mankind, semantic problems, semantic updates, semantic web algorithms, semantic web and search engines, semantic web feeds, semantic web part 4, semantic web vs web 2.0, service lifecycle, stochastic search, storage in oracle, using protege, weaving thread, web 3.0 blog, web technology topics, webservice lifecycle, zeitguiest, blog information extraction, blogs on semantic web, camp semantic, conference semantic web 2008, cross pollination wikipedia, eswc conference 2008, eswc tenerife, ftp p2p, information extraction open source, introduction semantic web
{kind=link}
Recently Commented Blog Entries